








论文阅读笔记,论文链接:https://arxiv.org/pdf/2107.14185.pdf
背景介绍
该文章发表在2021的ICCV会议当中,并且由浙江大学、武汉大学、Adobe联合发表。我们知道深度神经网络容易受到对抗样本的攻击,而对抗样本的生成是已知源模型的参数,然后在源模型的基础上生成对抗样本的。但是在现实情况下,我们是不可能知道模型的参数的,所以我们只有在源模型上生成对抗样本然后去攻击那些我们想要攻击的模型,这被称为黑盒攻击。而在源模型上生成的对抗样本,然后去攻击源模型,我们称之为白盒攻击。关于对抗样本的生成、白盒攻击、黑盒攻击的示意图如下所示。
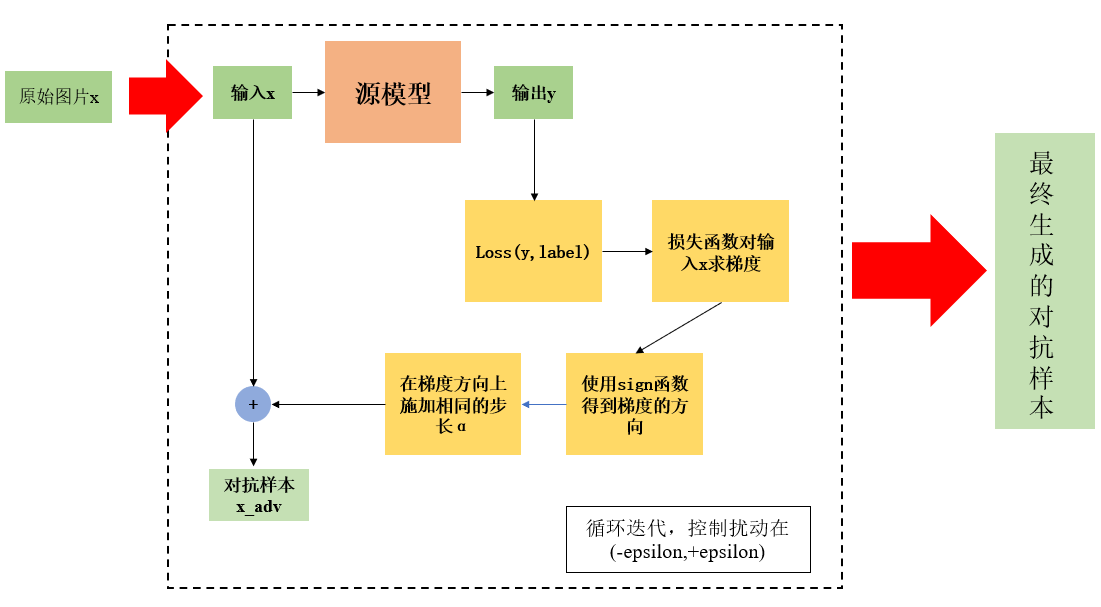
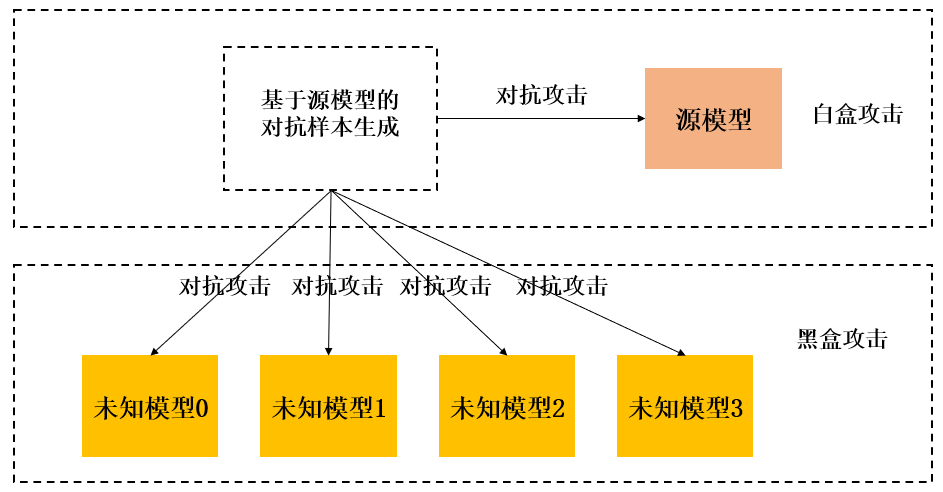
从上图可以很容易的知道,白盒攻击是已知源模型的参数进而求得对抗样本然后去攻击源模型,换言之,这种攻击方式就好像我知道你家门锁锁芯长什么样子,然后照着这个锁芯造一把🔑就行。但是黑盒攻击就好像是我知道了张三家锁芯的样子,然后我去造一把钥匙,我去拿这把钥匙去开别人家的锁。这样一来,除非我的钥匙是万能钥匙,要不然去攻击别人家的锁成功的概率不大。而现在我们需要解决的就是对抗样本在黑盒攻击中的迁移性。迁移性通俗来讲就是其可移植性,用刚才的例子说就是这把钥匙是万能钥匙的概率,迁移性越好,这把钥匙是万能钥匙的概率就越高,那么攻击模型的成功率也就越高。
作者在本文的贡献
- 他们提出了一个特征重要性感知攻击的方法,通过破坏主导不同模型决策的关键对象感知特性(也就是破坏主导模型决策的一些特性),从而提高对抗样本的迁移性。
- 他们分析了目前的工作中相对较低的迁移性背后的问题,也就是容易对特定模型的“噪声”特征进行过拟合,针对这些特征,他们引入聚合梯度,从而引导产生更具有迁移性的对抗样本。
- 他们在各种分类模型上的大量实验表明,与目前SOTA的迁移性攻击方法相比,他们所提出的FIA对抗攻击方法具有更好的迁移性。
FIA方法的主要思路
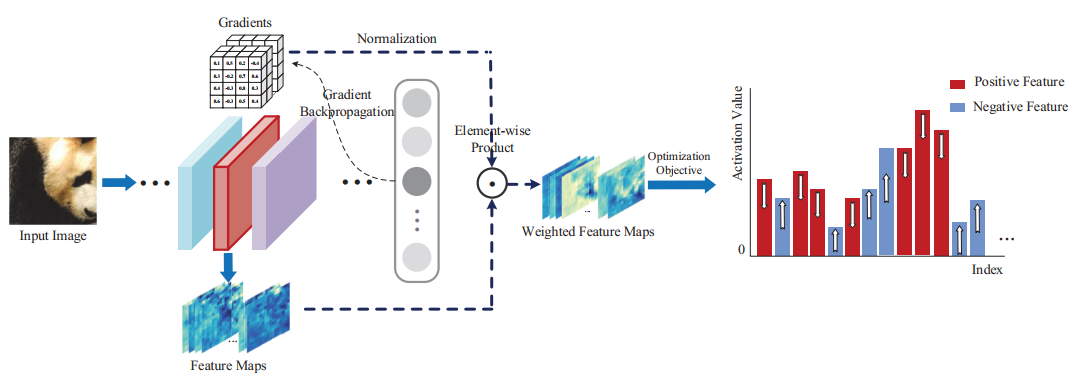
如上图所示,将图像输入到网络当中,然后从中间层提取特征图(这里也就是红色的部分,从红色部分提取特征图),然后进行梯度回传,然后将梯度与特征图进行点积(Element-wise Product)。这里可以明显的看出我们的梯度被当做是Importance Weight也就是重要性权重,相乘之后得到有权重的特征图。对于这些有权重的特征图我们的目的是抑制Positive Feature,然后提升Negative Feature。
当然说了上面这些,你可能还不懂,接下来我们详细介绍下Feature Importance-aware方法中的详细步骤,主要包含两个步骤,第一个是梯度聚合,第二个是整体的攻击算法。
梯度聚合
首先介绍一下如何求特征图的梯度,假设f表示我们的源模型,那么来自第k层的特征图就可以表示为$f_{k}(x)$,那么特征图的梯度也就是本文所提到的feature importance就可以表示如下图:
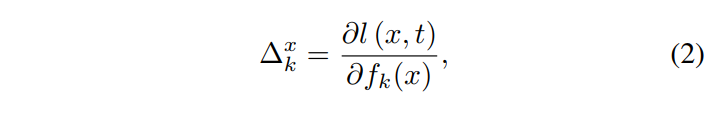
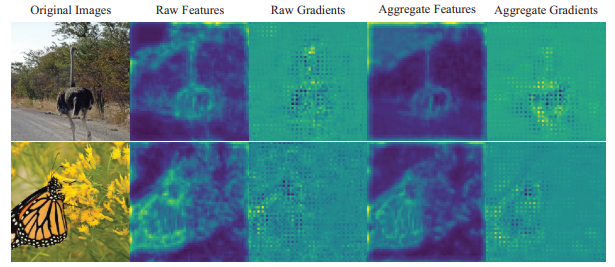
其中l(·,·)表示对于真实值t而言的逻辑值输出,那么这样相当于求特征图的梯度,将梯度可视化之后就如下图。其中Raw Features、Raw Gradients、Aggregate Features、Aggregate Gradients分别表示原始特征图、原始梯度图、经过聚合之后的特征图、经过聚合之后的梯度。从图中我们可以发现,原始梯度图和原始特征图在视觉上都是有噪声的,也就是在非目标区域上存在脉冲较大的梯度,这可能是由于模型特有的解空间造成的。但是经过聚合之后的特征图和梯度图就消除了这样的影响,只在目标区域存在脉冲较大的梯度。而对抗攻击的目的就是为了使得模型失效,那么我们只要提升聚合之后特征图在非目标区域的梯度减小特征图在目标区域的梯度,那么我们的攻击就能够成功。
不过在这之前,我们先来看一下,作者是如何进行特征聚合的。作者的特征聚合如下图所示,作者对原图像进行随机mask,也就是随机丢弃一些像素,然后得到我们的输入,之后将这些图像输入到模型当中经过然后通过梯度反向传播得到我们的梯度,之后将梯度相加得到聚合梯度。而聚合的梯度也就是我们的Feature Importance,特征重要性或者说特征重要度。

梯度聚合的公式如下,其中$M_{pd}$表示和原图x一样大的二值图,而$M_{pd}$服从伯努利分布,或者说是0-1分布。而C则是L2范数,用来约束聚合梯度。这样一来这个公式就很好理解了,首先将原图与我们的mask做一个点积,然后将结果输入到模型当中求第k层特征图的梯度,然后将这些梯度相加(聚合)然后使用L2范数来做一个约束,就得到我们的聚合梯度。而由于语义目标感知或者重要的特征或者梯度对上述的这个变换是鲁棒的,但是一些特定模型的梯度或者特征容易受到转换的影响,因此那些鲁棒的可转移的特征将会在聚合后被突出显示,而其它的梯度将会被中和。
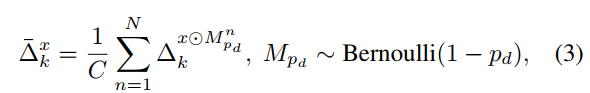
攻击算法
作者在这里设计出一个损失函数,如下面的公式4所示,将聚合后的梯度与特征图做点积,或者说将聚合后的梯度当做权重来与特征图相乘,而我们的目的是抑制重要的feature增强不重要的feature,那么只需要最小化我们的公式4就行了,将公式4代入到公式1,我们就得到我们最终对抗样本生成的公式5。攻击算法的详细步骤如下图算法伪代码所示。
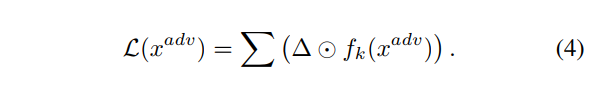
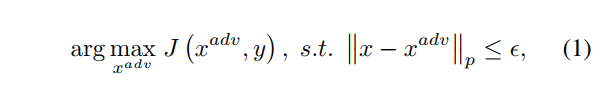
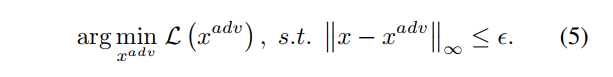

实验结果
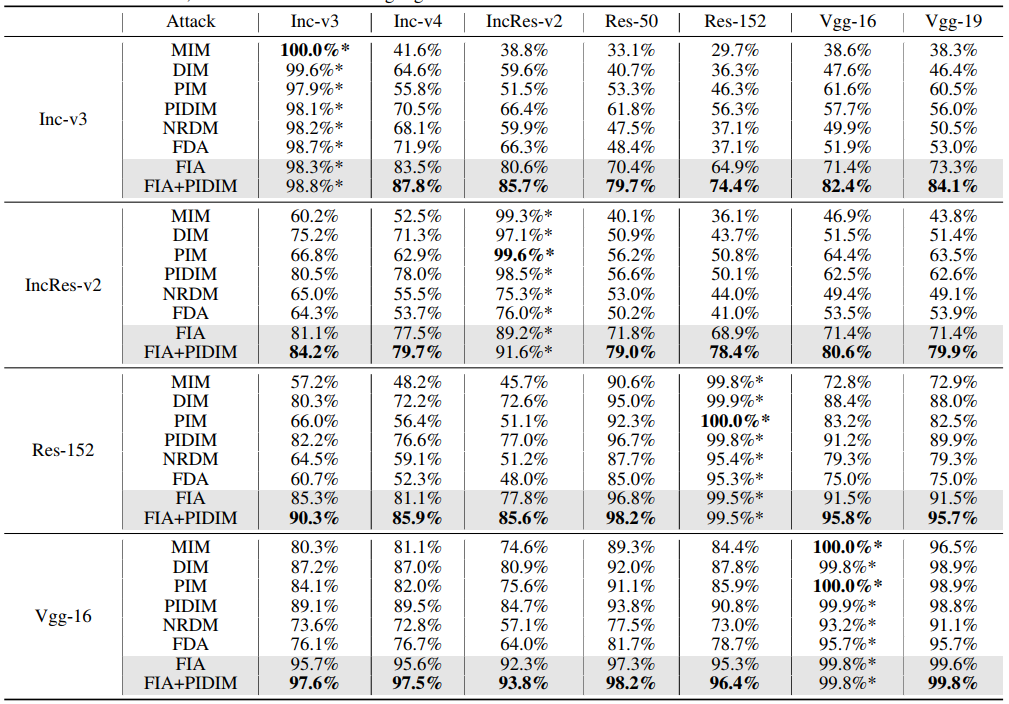
下图中FIA就是作者提出的方法,黑色加粗的就是攻击成功率最高的。最左边一列是源模型,Attack表示的是使用的攻击方法,右边那些就是要攻击的模型。其中FIA+PIDIM表示的是这两种方法的组合,总体来说,本文提出的方法在效果上确实是有东西的。
Q.E.D.

